
Hey, you! Thanks for visiting. I don’t know if you found this website via a search engine or by social media link or whatever but thank you for stopping by. As a matter of fact, this will be the topic of our little post: how to improve your SEO, from the technical side of things.
This will be the post about what you as developers can do about SEO. We’ll stay on the technical side of the equation, and leave the “snake oil salesmanship” to so-called “SEO experts, gurus and rockstars”. Therefore we’ll only mention the things that are proven to be SEO-friendly, and much more important than that, we’ll see how you can implement those things using some popular Web Development technologies.

So, let’s get started.
1. Clean URLs
Everybody (and their grandma) already know that so-called user-friendly URLs (or clean URLs) are good for SEO. Not only that, but clean URLs are pretty, easy to remember and cool.
Take a look at these examples of URL rewriting:
- http://localhost/index.php?view=content&id=1 -> http://localhost/content/1
- http://localhost/NewsList.aspx?year=2013&month=08 -> http://localhost/news/2013/08
In the previous two examples rewritten URLs are clearly better looking. They’re also more professional looking and people are just more likely to click on them. I mean, aren’t you?
Take a look at these examples of URL rewriting:
- http://localhost/index.php?view=content&id=1 -> http://localhost/content/1
- http://localhost/NewsList.aspx?year=2013&month=08 -> http://localhost/news/2013/08
In the previous two examples, rewritten URLs are clearly better looking. They’re also more professional looking and people are just more likely to click on them. I mean, aren’t you?
Now take a look at this example:
See what happened there? We not only made a cooler URL, but we managed to stick some words that help to describe the very nature of the article. And it certainly helps with Google and Bing. Haven’t you ever seen a search engine highlight a portion of the URL? Well, take a look:
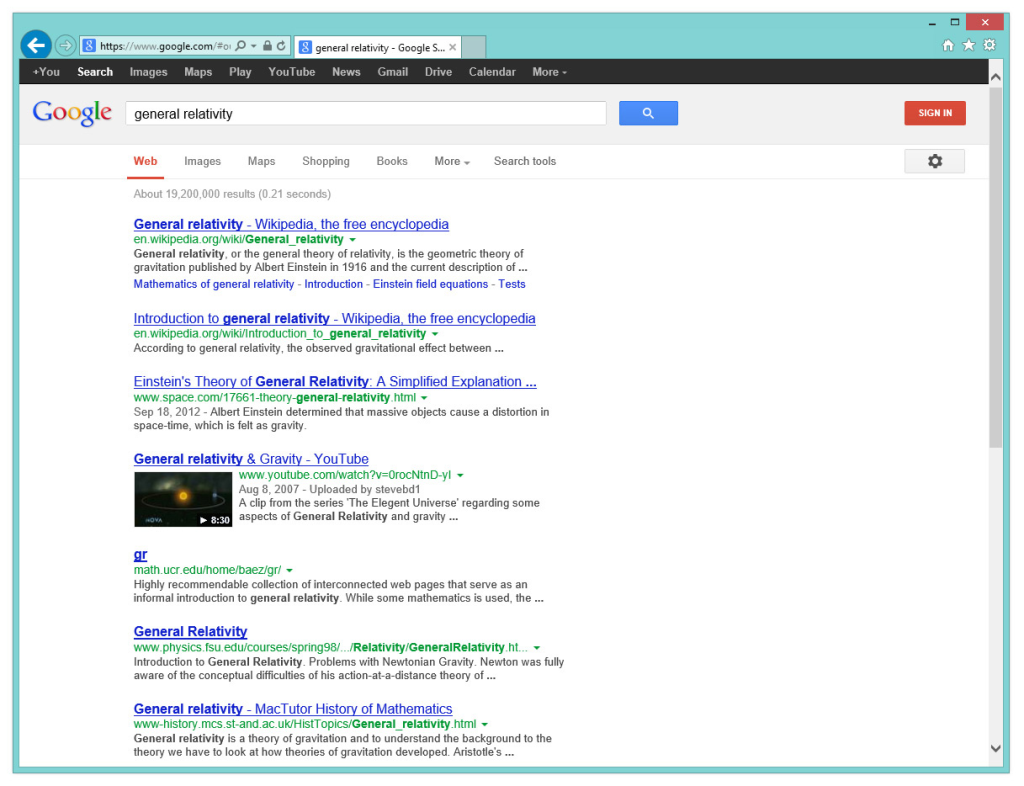
Of course, there’s another great advantage of URL Rewriting: original query strings used to retrieve blog posts can change and the rewritten URL can stay the same.
There’s also the security factor of rewritten URLs: they hide how the site works, meaning users don’t really know what query strings are used and what is happening behind the scenes.
OK, so, how do we get clean URLs? Well, it’s simple, really. There are a lot of technologies for getting clean URLs. First, of course, is rewriting.
1.1. URL Rewriting
The bottom line is you can use the IIS rewrite module for IIS which enables both simple and robust URL Rewriting based on request headers, IIS Server Variables and other rules.
You can download URL Rewrite from IIS.net website or install it using Web Platform Installer.
It’s a cool and easy-to-use URL Rewrite Module from IIS manager:
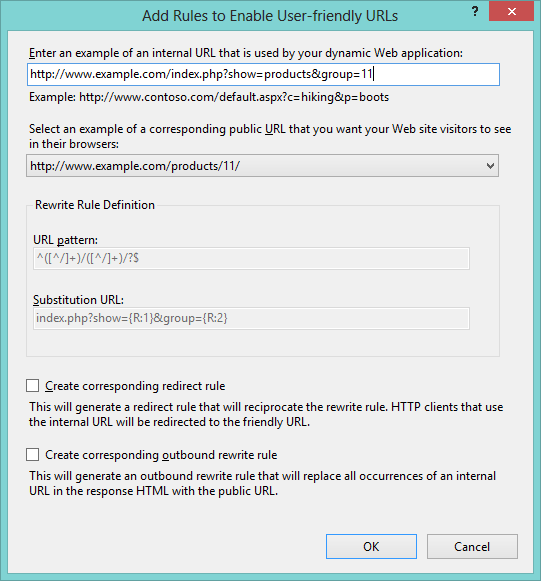
To learn more about URL Rewriting using IIS Rewrite module visit my previous blog post, or of course, more advanced Ruslan’s blog. He’s a Senior Software Design Engineer on the Microsoft Windows Azure team, so you’re bound to learn a lot more by visiting his blog.
Of course, you can URL rewrite on Apache too, there are lots of great resources out there to help you to get started:
1.2. ASP.NET Routing
So, what is ASP.NET routing? Well, routing is a feature that enables us to map specific browser requests to primarily ASP.NET MVC controllers and actions, but routing can be used with Web Forms as well.
In previous versions of MVC, routes were configured in Global.asax, but in newer versions of MVC, routes are configured by editing the “RouteConfig.cs” inside the “App_Start” folder.
When you create a new MVC 4 project, for example, you will have the following routing config already entered for you:
public class RouteConfig
{
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
routes.MapRoute(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional }
);
}
}
The default route lists three parameters, with configured default values. For example, the default value for a controller is “Home”. If the “controller” parameter is missing, it will default to “Home”. If the action is missing, it will default to “Index”, and if id is missing, it will default to an empty string.
So, if you run your basic MVC application, by default “Home” controller and “Index” action will be used. This means that if we wanted to have a URL like http://localhost/posts/2008 we can enter a new route like this one:
routes.MapRoute(
name: "Posts",
url: "posts/{year}",
defaults: new { controller = "Blog", action = "Archive" }
);
So this route will match a request that starts with “posts” and maps it to the “Blog” controller and “Archive” method. That is if you put that route above the “default” route
It’s important to notice as you play with routes that ordering is important because as soon as a route is matched, the processing stops. For example, if we put our route behind the default route, the default route will be matched and it will map our request to the “posts” controller which does not exist. So, if we do it like this:
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
routes.MapRoute(
name: "Posts",
url: "posts/{year}",
defaults: new { controller = "Blog", action = "Archive" }
);
routes.MapRoute(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional }
);
}
We get this:
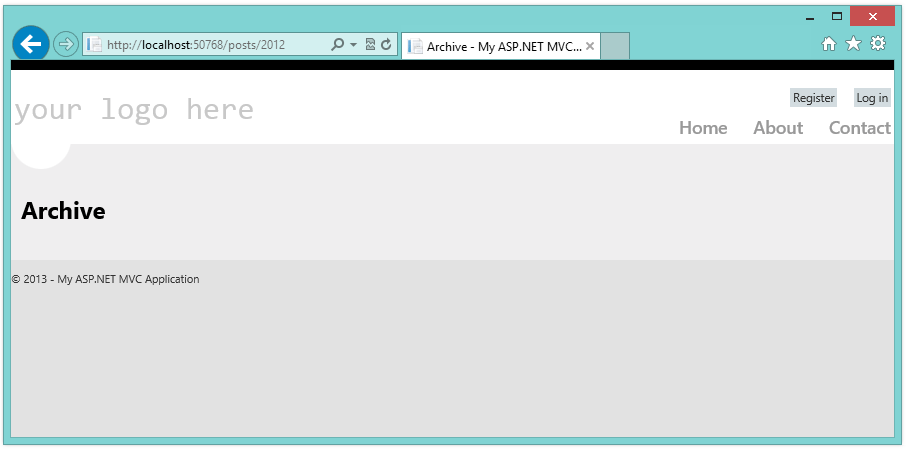
So, it really doesn’t take a lot of imagination (or programming, really) to use routing to help us make our desired clean URLs. For a deeper understanding of routes and various routing tricks check out Phil Haack’s blog.
2. Duplicate content problems
There are some doubts about whether is this actually a problem. For example, in this video, Google’s Matt Cutts kinda says duplicate content shouldn’t be a problem, but I think it’s better to stay safe. If Google is THAT smart, maybe other search engines aren’t.
Anyway, duplicate content can be a problem, because often search engines don’t know which version of the document to include on the result pages.
So, what exactly IS “duplicate content”? Well, duplicate content can happen:
- If the same page is accessible via more than one URL, like for example:
http://example.com/products.php?show=red
http://example.com/products/red
Even this example can be considered duplicate content:
http://example.com/index.aspx
http://example.com/Index.aspx (Notice the capital letter I) - If the page’s content is the same, but there’s some query string parameter that doesn’t influence what’s on the page, like:
http://example.com/shownews.aspx?sessionId=123
http://example.com/shownews.aspx?sessionId=321 - Printer or specific device-friendly version of the same page with the same content:
http://example.com/genericpage.html
http://example.com/printSpecific/genericpage.html
In all those examples the search engine can be in doubt which page to show.
So, what to do about it? Well, you basically have two options:
- Do an HTTP 301 Redirect
- Specify the canonical page using rel=”canonical”
2.1. The HTTP 301 Redirect
The HTTP 301 status code means that the page a user (or a bot) is trying to visit has moved to a new location. By using 301 redirects to a new location you’re letting the user agents know the new location of the page.
So, you basically need to decide which is the preferred URL of a page and when a user or a spider visits any other URL version of that page redirect them to a preferred URL.
The very act of redirecting is basically easy. You have several options to use, including .htaccess on Apache servers or through URL Rewrite module on IIS.
Here are some helpful links:
- Apache HTTP Server Tutorial: .htaccess files
- Apache mod_rewrite guide
- Apache Module mod_alias
- Configuring HTTP Redirection in IIS 7
- URL Rewrite Module – Video Walkthrough
- URL Rewrite Module tutorials
Of course, you can also implement HTTP 301 redirect directly from your preferred server-side technology:
PHP – Use the header function:
header("HTTP/1.1 301 Moved Permanently");
header("Location: http://www.new-url.com");
exit();
ASP.NET Web Forms – Response:
Response.Status = "301 Moved Permanently";
Response.AddHeader("Location", http://www.new-url.com);
Response.End();
ASP.NET MVC:
There are actually a few good methods you can call from the controller:
return RedirectPermanent("http://www.new-url.com/");
return RedirectToActionPermanent("action", "controller", new { id = 1, title = "new-title" });
return RedirectToRoutePermanent("route-name", new { id = 1, title = "new-title" });
TIP: If you’re using slugs in your URLs, but get the data from the database, using a numeric value like for example, Stack Overflow does, you should do a redirect each time when you get a different slug from the one stored in your database.
So, the basic principle is kinda like this:
- Have a content slug (for example slug for this content is: “SEO-for-developers”) stored in the database. A slug can be automatically generated or have users enter them via CMS. Whatever.
- Use a numeric ID to get the data from DB.
- When you have the data from DB, compare the stored slug with the one you got from the query string.
- If they don’t match, do a 301.
2.2. Specifying the canonical page
What is a canonical page? Well, to quote Google:
A canonical page is the preferred version of a set of pages with highly similar content.
So, it’s kinda like a permanent redirect to a preferred version of the page. But, how do we “specify canonical page”? Well, we “Add a rel=”canonical” link to the head of the section of the non-canonical version of each page. “.
The correct procedure would be to put a “canonical” with a preferred content URL inside the head section of each duplicate content version, like this:<link rel=”canonical” href=”http://salopek.eu/content/31/hello-world” />
Using the canonical link tells the Bing, Yahoo and Google search engines where the preferred content is.
How to generate and display the canonical link? Simple, there are plugins for many popular blogging tools and CMS solutions. And if there are none, a simple google search will give you lots of plugins and useful options:
- WordPress plugins
- eZ Canonical for eZ Publish
- Setting canonical tags for categories in Magento on Stack Overflow
- Canonical meta link package for Umbraco
Still, if you don’t find a plugin for your CMS, it should be really easy to write one for yourself. After all, this blog post is named “SEO for Developers” : )
Just remember, link rel=”canonical” can contain both absolute and relative URLs, so don’t sweat about it too much, just pick a format and go with it.
3. Pagination
What’s the deal with pagination and paginated content? Well, the deal is, the content is spread out across multiple URLs, and unless you have a View-All page, the search engine may have trouble understanding that content is consolidated and view each page as slightly different content, which means it can reduce the impact of your content as it’s spread out across multiple pages and no single page gets a big impact.
Link rel=”prev” and like rel=”next” basically help search engines understand each individual page as a part of the “series” of content, which in essence helps them to present the best, most relevant page to the user (usually page no. 1).
So, what’s the structure of link rel=”prev” and link rel=”next”? It’s really simple, so let’s see an example of paginated content that spans three pages:
- The first page in a series of paginated content:
No rel=”prev”
rel=”next” to next page:<link rel=”next” href=”http://example.com/page/2″ /> - The second page in a series
Both rel=”prev” and rel=”next”
rel=”next” to next page <link rel=”next” href=”http://example.com/page/3″ />
rel=”prev” to previous page <link rel=”prev” href=”http://example.com/page/1″ /> - Third and last page in a series:
No rel=”next”
rel=”prev” to previous page <link rel=”prev” href=”http://example.com/page/1″ />
How to do that? Well, it’s simple, really. I’m betting that if you have a pagination system in place you can easily access the variables needed to generate the mentioned tags. For example, this is how you would do it using ASP.NET MVC:
@RenderSection("seo", required: false)
View:
@section seo {
@if (Model.HasPreviousPage)
{
<link rel="prev" href="@Url.Action("Index", "Home"
, new { page = (Model.PageIndex - 1) }))" />
}
}
Advanced tip: the added bonus of adding the rel=”next” is that Firefox prefetches the “next” page so it loads faster:
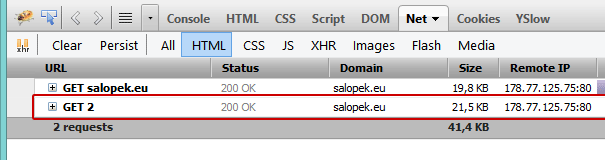
Also, it doesn’t hurt to set the page title to show the visitor on what page they’re on: salopek.eu | Web Development | Web Design | Networking (Page 1 of 8)
4. Site speed
This is a quote from the Using site speed in web search ranking official Google webmaster central blog:
“…as part of that effort, today we’re including a new signal in our search ranking algorithms: site speed.”
So, the bottom line is: You should strive for small loading times for your website. How to do this? Well, there are lots of ways:
4.1. Use CSS Sprites
CSS Sprites enable us to store the graphics we need to display menus, icons or buttons in one big image while showing only a part of that image at a time. This helps to reduce the number of HTTP requests, which increases site speed.
This isn’t really a developer thing, it’s more a designer thing, but you can check out my earlier blog post for more information on CSS Sprites.
4.2. Use a CDN
You can load many great tools and libraries from the CDN:
- Microsoft Ajax Content Delivery Network
- Google Hosted Libraries
- cdnjs – They “host it all – JavaScript, CSS, SWF, images, etc!
4.3. Minify site resources (JavaScript, CSS …)
This means: “remove all unnecessary characters from resources to make them smaller and lighter.” There are tools to do this, like JSMin or YUI Compressor, but since you are a developer, you can even write your own, if you want to learn something new and spend a little free time.
For example, I use the new bundling and minification features in ASP.NET.
These few are only examples of what can you do. There are of course other things you can do to improve site speed. A great place to start would be checking out Yahoo’s Best Practices for Speeding Up Your Web Site.
Also, there are lots of great tools to help and assist you:
- YSlow, a free tool from Yahoo!
- PageSpeed Tools on Google Developers – Make the Web Faster
- WebPageTest
5. Other considerations Developers should pay attention to
5.1. An issue with separate mobile URLs
If you use redirects for mobile devices (which you shouldn’t do) you should include link rel=”alternate” in your desktop pages.
5.2. Know the HTTP Status Codes
A lot of wins come from knowing the HTTP Status Codes and using them correctly. Here’s the list on Wikipedia. Study it. Know what status code to use and when.
For example, if a page doesn’t exist, returning a 200 OK status code and a “Page not found” message is BAD.
5.3. Moving to a new domain – the right way
301 Redirects should always be from an old URL of the content to a new URL of the same content, for example:
http://old-domain.com/example-page-123.html to
http://new-domain.com/example-page-123.html
You should never redirect all the traffic from the old domain to the new domain. Do NOT do this:
http://old-domain.com/example-page-123.html to
http://new-domain.com
You can also tell Google (using Webmaster tools) that your website has moved to a new domain.
To do this, simply login to Webmaster Tools, click on a site and in the dropdown preferences menu select Change of Address.
5.4. Add social sharing buttons to a site
While social buttons aren’t having a direct impact on SEO, they make the site’s content much easier to share with others using their favourite social networks. This means their friends, followers or what have you will visit your site and maybe share it further, maybe even link to it on their own site etc. So, how to share?
Well, every major social network has its share widget now, which you can easily implement on your site:
Also, when implementing a share widget make sure to load JavaScript asynchronously.
5.5. Use Schema.org tags
Schema.org tags are another result of collaboration between Google, Bing and Yahoo. These tags help developers and webmasters to indicate to the search engines what their content is all about. If these tags are properly structured, search engines can read them and understand the meaning of a certain web page content. This is how you get those rich snippets you get to see when searching.
Getting started using schema.org tags is easy. For example, this is how you would set up the tags to describe a book:
<div itemscope itemtype="http://schema.org/Movie"> <h1>Avatar</h1> <span>Director: James Cameron (born August 16, 1954)</span> <span>Science fiction</span> <a href="../movies/avatar-theatrical-trailer.html">Trailer</a> </div>
This does not have any effect on ranking at this time, but your site can look better in the search results, which can lead to more traffic.
Conclusion
This concludes our little list of stuff we as developers can do to help SEO both directly and indirectly (by giving the right tools to people that may know more about SEO than we). Note that I included only stuff that’s proven and that people who work at the search engines tell us themselves. If you feel I forgot something important, feel free to leave a comment and a link to your site. Please, no shady or black hat stuff, as this won’t help people and your comment will be deleted.
Also, do yourself a favour and stay away from guys that promise stuff they can’t deliver (or possibly can, but using techniques that will get penalized in the next search engine algorithm update). My advice is: try to write good and helpful content, stick to common sense, and use keywords in articles wisely (don’t blindly stuff your articles full of keywords)n and the results will come.
Thank you for your time.